Archive.org, ¿Cuantas veces hemos utilizado esta herramienta online? – Rescatar contenido para reutilizarlo en nuestros blogs o paginas, ver el aspecto que tenia la web antes de comprarla para nuestra PBN, ver posibles indiciones de SPAM o malas practicas, recuperar el site entero para recuperar su antiguo posicionamiento, etc. etc. etc. Yo creo que perdi la cuenta. Hoy hablaremos de http://archive.org y como facilitar la recuperacion de toda una web facilmente.
Programa para bajar una web al completo desde Archive.org
¿Alguna vez has querido recuperar una web desde la Internet Archive Wayback Machine y te has encontrado problemas? Con esta pequeña guía aprenderás a hacerlo de forma fácil, rápida y gratis. Para ello haremos usaremos la herramienta Wayback Machine Downloader de Hartator, que por defecto descargará la última imagen de la web disponible en el portal de “Archive”.
Como requisitos previos, necesitas tener Ruby instalado en tu sistema. Si no lo tienes, puedes instalar Ruby descargando el instalador desde el repositorio oficial en https://rubyinstaller.org/downloads/. Preferiblemente instala versiones 2.2.x de 32 bits. Las versiones posteriores o de 64bits no son tan estables y pueden dar problemas.
Para instalar la herramienta de descarga de webs usaremos la consola de Ruby, así que la abriremos tecleando CMD en buscador del menú de inicio de Windows.
Una vez en la consola, teclea el siguiente comando: gem install wayback_machine_downloader.
Si da error de certificado (aparecerá algo así como “Certificate verify failed”) como en la siguiente imagen, podemos solucionarlo cambiando el origen de descargas de “gemas” para que se puedan instalar desde http en lugar de https. Para ello ponemos en la consola el siguiente comando: gem sources -a http://rubygems.org/ y aceptamos poniendo “Y” y pulsamos Intro.
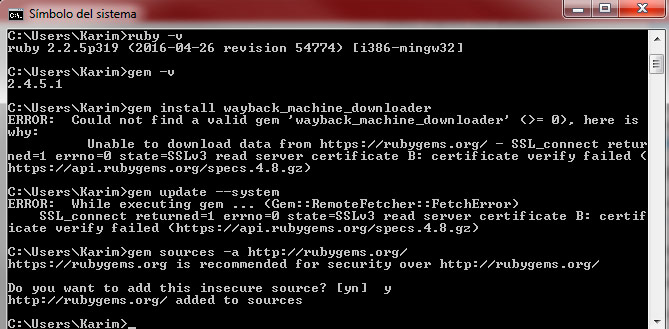
Una vez nos sale aceptado el cambio, volvemos a probar instalar la herramienta de descargas con el comando: gem install wayback_machine_downloader.
Ahora, si!! ya podremos descargar la web que nos interese poniendo en la consola el comando: wayback_machine_downloader http://nombredelaweb.com. La web se descargara por defecto al directorio: C:\Users\tunombredeusuario\websites. Dependiendo del tamaño de la web, este proceso puede tardar desde unos minutos hasta unas horas. Lo más probable es que estés descargando alguna web de un dominio recién con métricas interesantes, y estos por lo general suelen ser páginas muy grandes, así que tocará relajarse y esperar. En este caso vamos a descargar la web de mumsprivee.
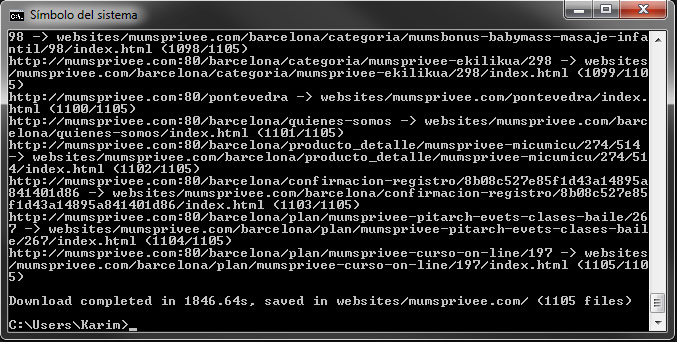
Finalizada la descarga, accedemos al directorio y revisamos la web descargada. Veremos que los archivos de la web estarán organizados en carpetas que serán el nombre de la URL y dentro de cada carpeta habrá un archivo index.html.
Abrimos cualquier index.html con Notepad++ o nuestro editor de código preferido y hacemos un pequeño repaso del código fuente. Todos los archivos estarán referenciados a URL’s de la web original. Los enlaces también, es decir, en los links aparecerán rutas absolutas del dominio original. Esto implicará que la web de momento es inútil ya que no nos estará cargando CSS, JS, y los enlaces nos llevarán a direcciones erróneas.
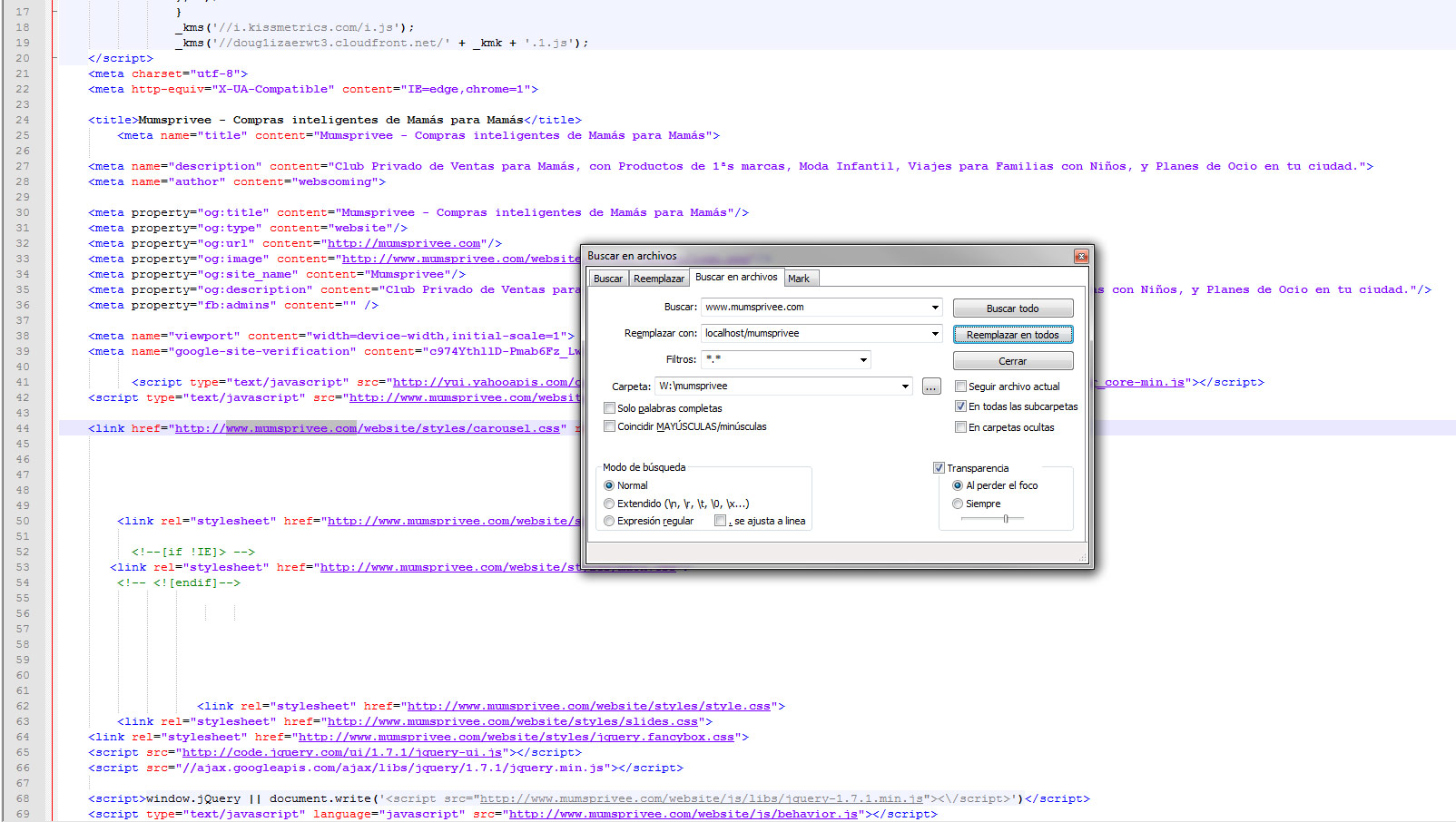
Realizamos un Buscar y Reemplazar masivo de toda la carpeta, reemplazando las rutas erróneas y las sustituimos por las actuales. Nosotros colocamos toda la carpeta de la web en la raíz de nuestro servidor local (Localhost en nuestro caso) y sustituimos http://nombredeweb.com por http://localhost/nombredecarpeta.
Borramos o deshabilitamos todas las cosas que no nos interesen en todos los archivos, por ejemplo el antiguo código de Google Analytics si lo tuviera.
Ya podemos visualizar la web y navegar por ella en nuestro servidor local. Si queremos subir la web a un nuevo dominio, realizamos otro “Buscar y reemplazar” masivo cambiando de nuevo las URL’s que hay (las que hemos cambiado en el paso anterior) por las del dominio que usaremos, y subimos los archivos por FTP.
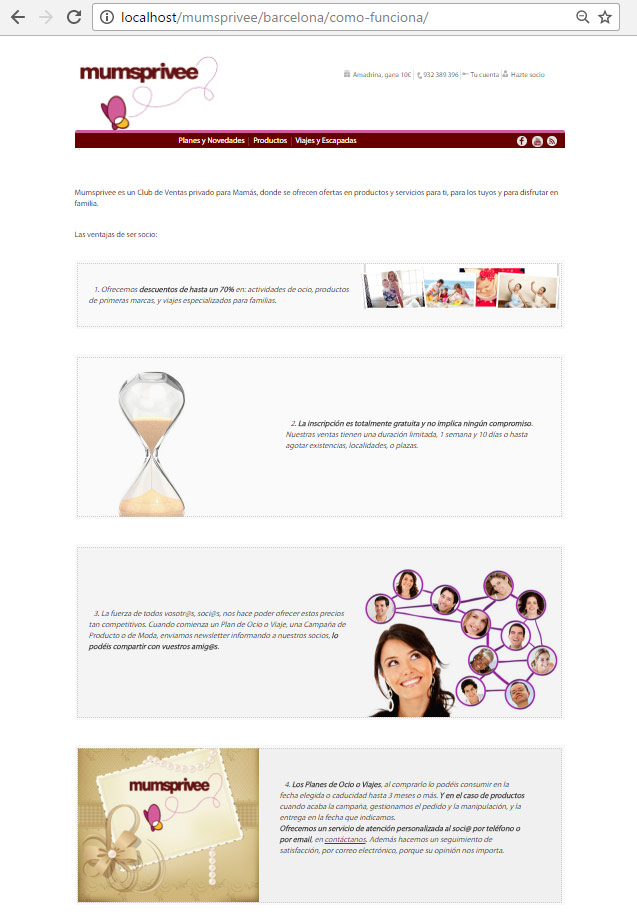
Eso es todo! Las partes dinámicas de la web, como por ejemplo el Login o los formularios no funcionarán de forma correcta, lo cual es lógico dada la forma en que se guardan las webs en Archive.org (No disponemos de las funciones PHP y la base de datos). Si lo quisiéramos hacer accesible y editable, se puede hacer importando todos los datos a una instalación limpia de WordPress por ejemplo, pero eso ya es otro tema!
Antes de terminar nos despedimos desde las instalaciones de diseño web https://www.morethanweb.es – esta gente son unos maquinas, asi que si quereis buenos desarrolladores web, contactar con ellos que del SEO nos ocupamos nosotros. https://www.pasionseo.com.
imagen de portada fratuita del portal: http://freepik.com
Seguramente hay más métodos para realizar la misma tarea, pero este es el método más sencillo, fiable y directo que hemos probado hasta ahora.
¿Has usado alguna vez este o otros método para descargar webs desde Archive.org?

4 Comments